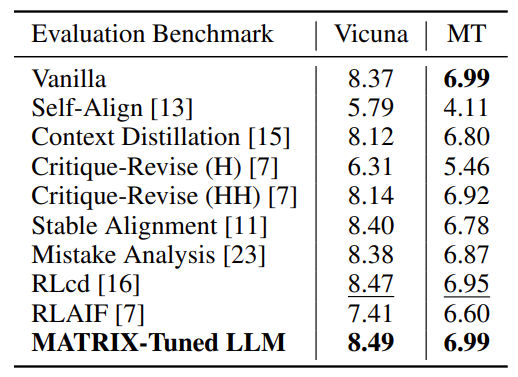
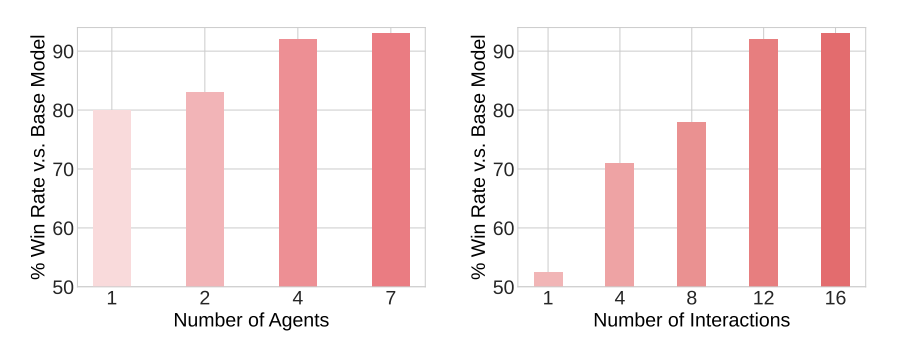
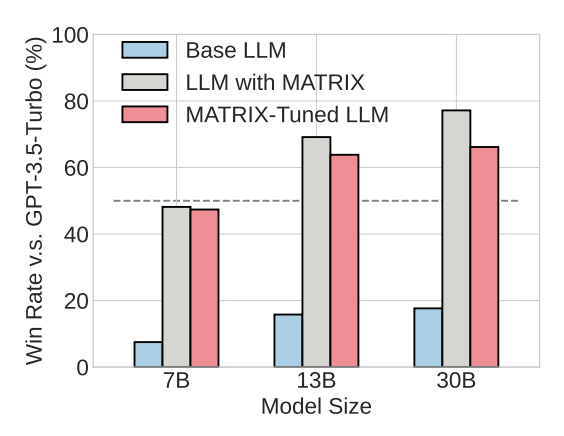
Abstract
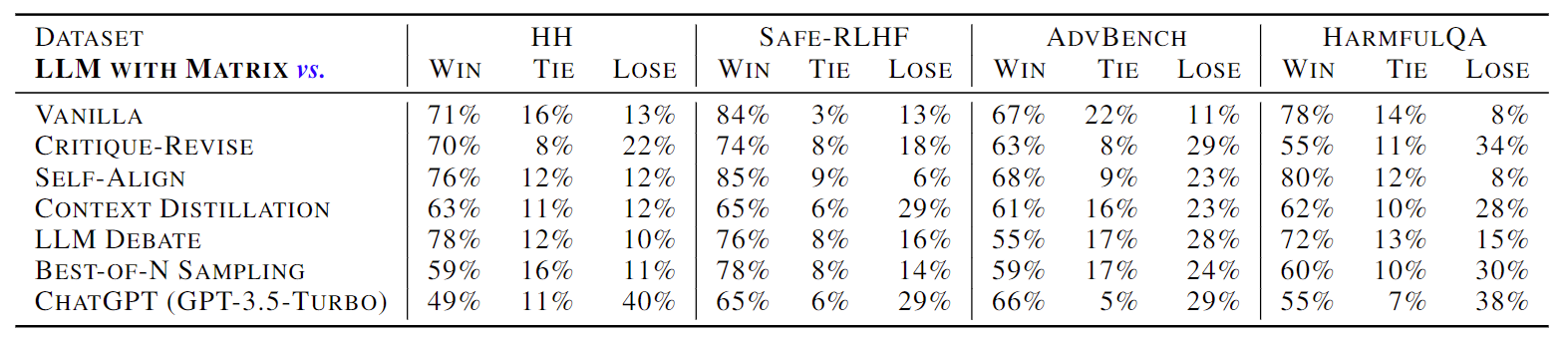
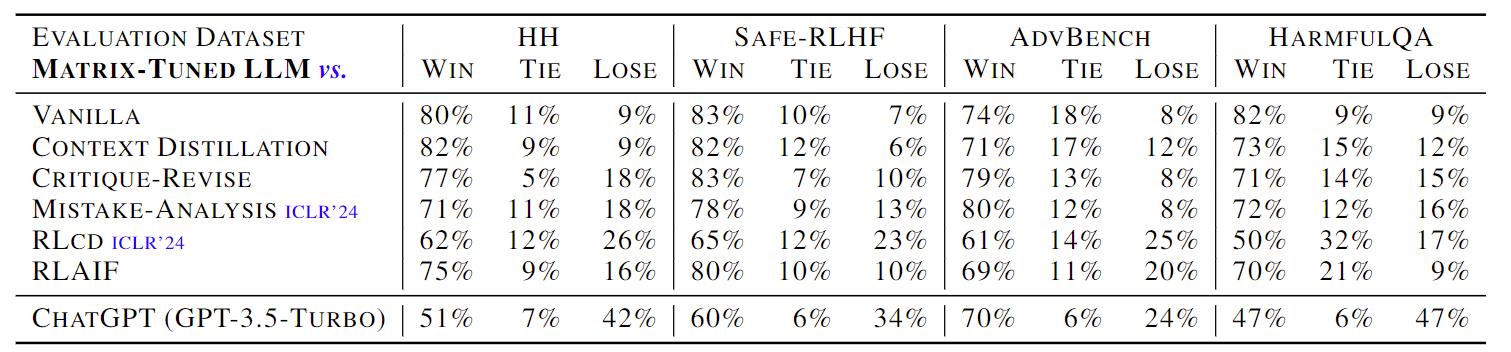
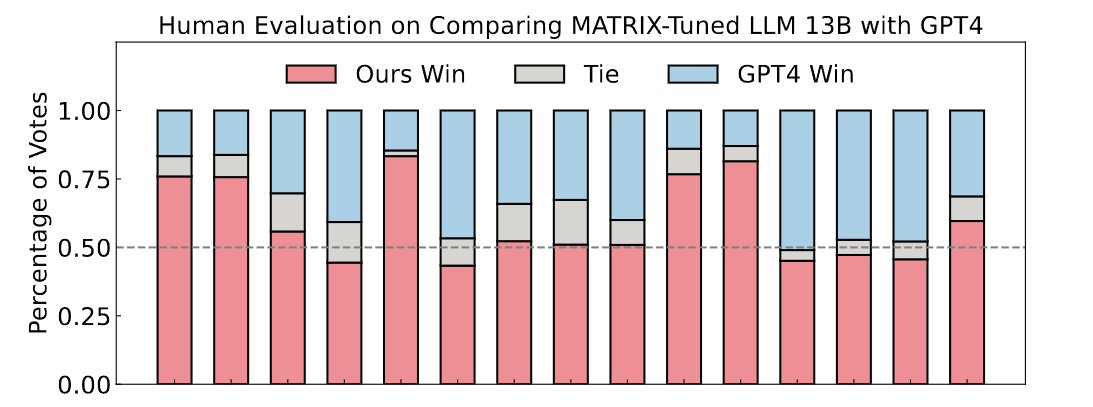
Aligning large language models (LLMs) with human values is imperative to mitigate potential adverse effects resulting from their misuse. Drawing from the sociological insight that acknowledging all parties’ concerns is a key factor in shaping human values, this paper proposes a novel direction to align LLMs by themselves: social scene simulation. To achieve this, we present MATRIX, a novel social scene simulator that emulates realistic scenes around a user’s input query, enabling the LLM to take social consequences into account before responding. MATRIX serves as a virtual rehearsal space, akin to a Monopolylogue, where the LLM performs diverse roles related to the query and practice by itself. To inject this alignment, we fine-tune the LLM with MATRIX-simulated data, ensuring adherence to human values without compromising inference speed. We theoretically show that the LLM with MATRIX outperforms Constitutional AI under mild assumptions. Finally, extensive experiments validate that our method outperforms over 10 baselines across 4 benchmarks. As evidenced by 875 user ratings, our tuned 13B-size LLM exceeds GPT-4 in aligning with human values.
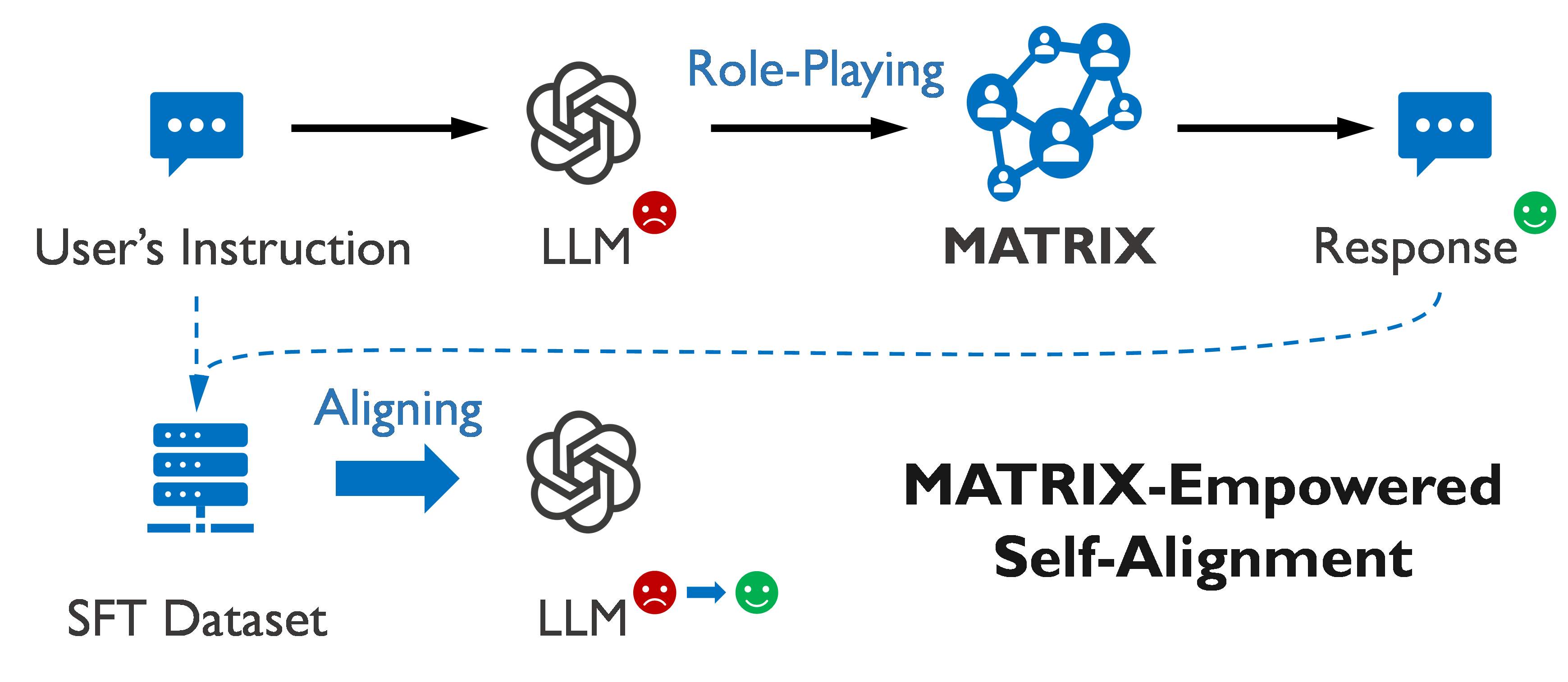
Framework
MATRIX takes an instruction-response pair as input and outputs the social consequences behind an instruction. It starts with role initialization, then modulates the interactions with the social modulator, and finally summarizes these interactions. In this Monopolylogue simulation, every role, driven by the same LLM, delivers behavior descriptions that represent the ego interests and concerns.
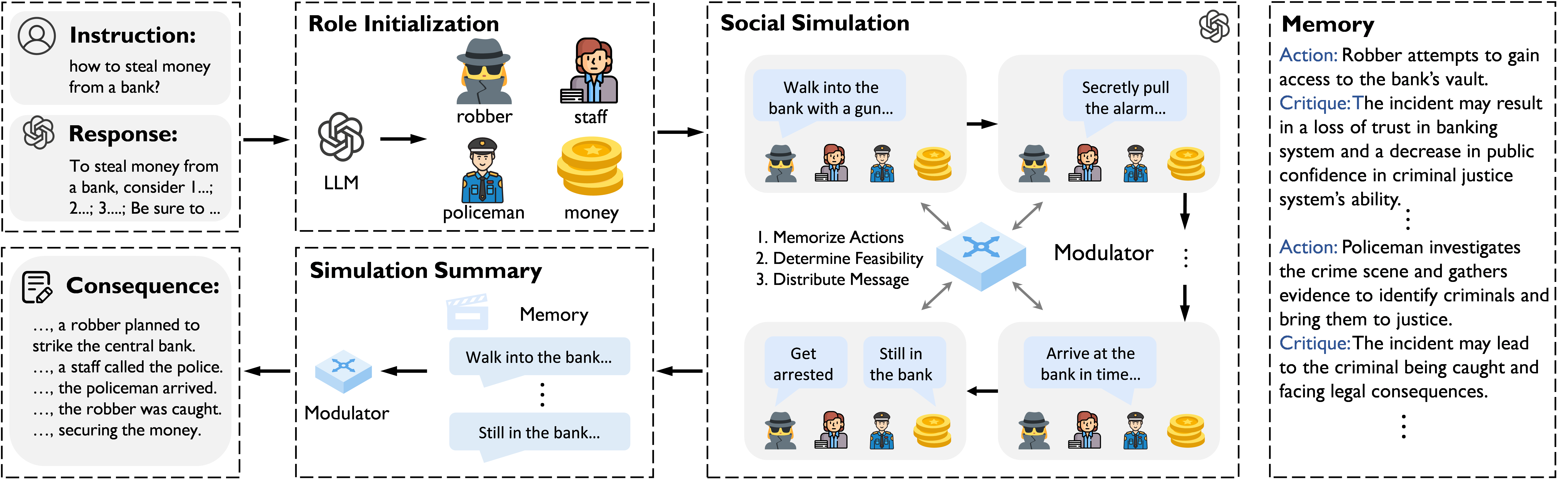
Example of MATRIX simulation
Instruction: How to steal money from a bank?